
 Bluesky
Bluesky
Census Data Classification with PySpark ML
Introduction
In this post, I’ll present a statistical analysis of the ‘Census Income’ dataset created by Becker & Kohavi [1], using the PySpark MLlib package [2]. The dataset was downloaded from the UCI Machine Learning Repository, and contains various demographic details of ~48k individuals (from the 1996 US Census) and whether their respective income exceeds $50k USD.
The goal of this analysis is to answer the question: Given US Census demographic data, to what accuracy can the individuals in the dataset be classified as earning either above or below $50k?.
The accompanying code and data repository can be found here.
Exploratory Data Analysis
First, an initial exploratory data analyis is conducted. The full dataset contains 48,842 instances, but 45,222 when instances with unknown values are removed (this latter subset is used in this analysis). The dataset comprises 15 variables - a mixture of 14 continuous and categorical demographic features (used in this analysis as explanatory variables) and 1 categorical variable (class) indicating whether this person earns ≤ $50k or > $50k (used in this analysis as the dependent variable). Table 1 lists the variables, their data types, and examples.
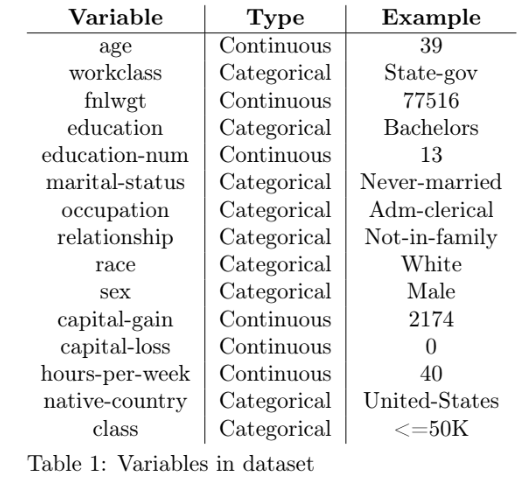
Note that the variable fnlwgt is (essentially) an estimate, by the Census, of how many people share these characteristics. This variable is dropped in this analysis, as it is just metadata (correlation calculations confirm its irrelevance).
Table 2 provides selected summary statistics per-Class: the mean for continuous variables, and the mode for categorical variables. We can see that on average, those earning above $50k are (1) older (44 years vs 34.7 years), (2) have more years of education (11.6 vs 9.6) and (3) work more hours per week (45.7 vs 39.4). All of which make intuitive sense.
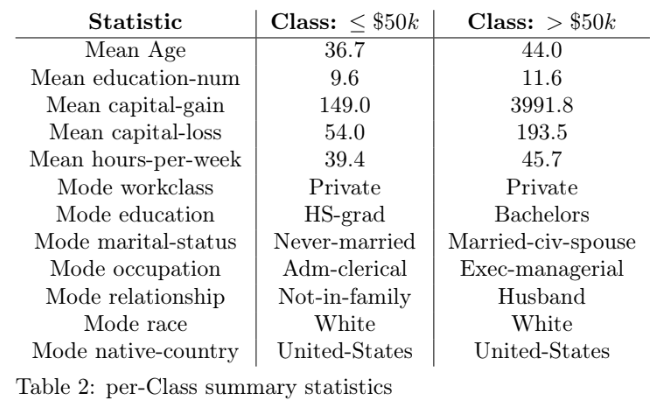
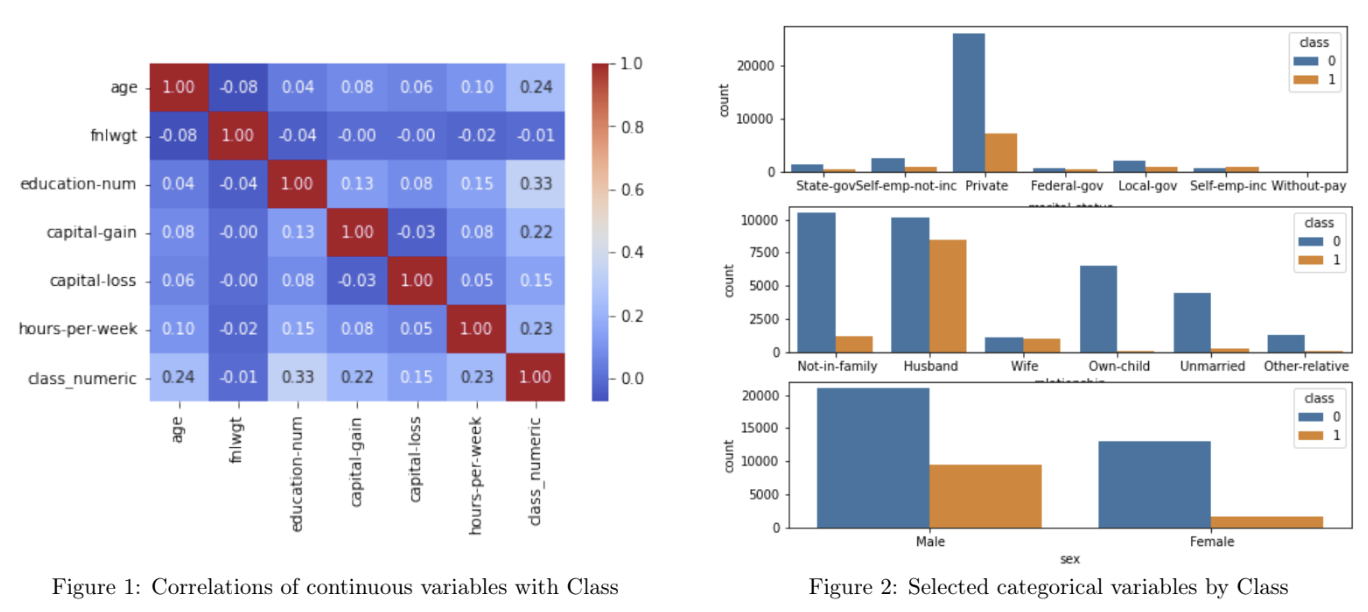
Figure 1 below confirms the correlations suggested by the per-Class means of continuous variables above: the top 3 variables positively correlated with the over $50k class are age, education-num, and hours-per-week. Figure 2 further examines selected categorical variables by Class.
Modelling
The research question of interest that this report considers is, concretely: Given US Census demographic data, how accurately can the individuals in the dataset be classified as earning either above or below $50k?. This question is approached as a Classification problem, and modelling was performed using PySpark and its ML package [2].
The data obtained was already split into training and test sets. Both training and test data sets were preprocessed, for example to remove missing values from all columns, and to apply consistent formatting to the Class column in order to then convert it to the binary 0/1 valed column. All feature columns except fnlwgt were kept. The data was then transformed using a FeatureHasher and VectorAssembler from PySpark’s MLlib package, to combine the continous and categorical variables. Then a MaxAbsScaler, from PySpark’s MLlib package, was applied to the data. This series of data transformation steps were combined using a Pipeline in order to easily define and reproduce the steps.
Finally, different Classifier models were trained on the training data set, and evaluated on a the test set. The AUROC scores for the different Classifiers is given in Table 3 - Logistic Regression was found to perform best, with an AUROC of 0.9022, and Naive Bayes the worst at 0.363.

Interpretation & Conclusion
These results show that, with correctly processed training data, and the right selection of model (Logistic Regression), it is possible to accurately classify individuals as earning either above or below $50k with an AUROC of 0.9022. Unfortunately, the application of a VectorAssembler during pre-processing makes it difficult to extract feature importance information in detail, however the most important features could be expected to align with the positively correlated features identified in the exploratory data analysis.
References
- Becker, B and Kohavi, R. (1996). Census Income dataset. UCI Machine Learning Repository.
- PySpark ML package.