
 Bluesky
Bluesky
Sentiment Analysis with scikit-learn, nltk and word2vec
Introduction
This post presents a process of performing sentiment analysis the Starbucks Reviews Dataset from Kaggle. The goal was to classify reviews as either Positive or Negative. Two models were developed for this purpose, and their performances compared.
The accompanying code and data repository can be found here.
Data
The ‘Starbucks Reviews Dataset’ contains data from online customer reviews of Starbucks coffee shop locations. The dataset contains 850 samples containing (among other features) a text review and a numeric rating (on a scale of 1-5).
First this data was cleaned up to remove incomplete samples: Only 705 of the 850 samples contained a numeric rating, and of those only 703 also contained an actual text review. This set of 703 reviews and ratings was used for modeling.
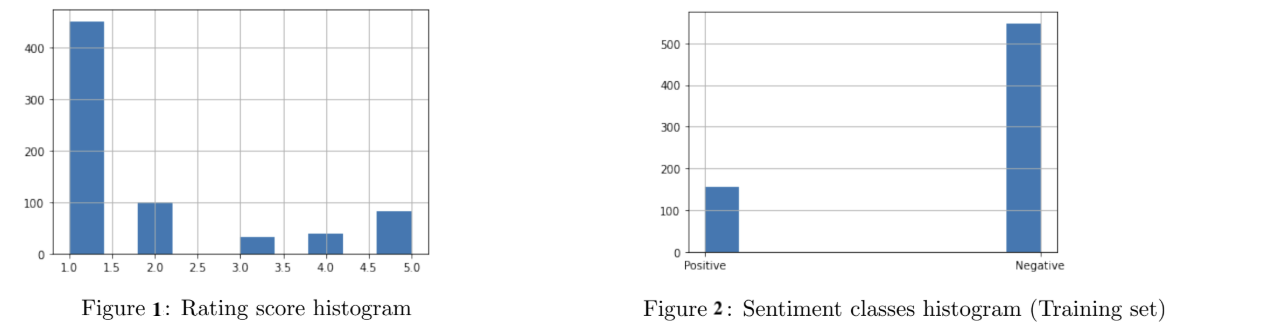
The distribution of the numeric ratings is given in Figure 1. We can see that the distribution of ratings is right-skewed (more negative ratings). A modelling choice was made to set a threshold of 3 and above to be a Positive rating, and below 3 to be a Negative rating - these would be the class labels. Figure 2 shows the resulting distribution of sentiment classes (Positive/Negative) - with a clear class imbalance.
The text reviews were then pre-processed, with the following steps applied to each document:
- Remove hyperlinks
- Make all words lower case
- Remove new line characters
- Remove characters that are not whitespace and not in English alphabet
- Remove words that are in the stopwords list provided by the
nltkpackage - Remove the word ‘Starbucks’
- Perform stemming, using the
PorterStemmerfromnltk
Modelling
The reviews dataset was used as follows:
- The text reviews were vectorized to create the independent variables
- The numeric ratings were converted to sentiment classes, these would be the class labels (the dependent variable ’Y’)
The reviews dataset was then split into training and test sets, with a 75%/25% split (with shuffling).
Two models were developed, both based on RandomForestClassifier from scikit-learn. A Random Forest Classifer was chosen as it is robust to datasets with class imbalance (as is the case here). Where the two models diverge, however, is in the choice of text vectorization method:
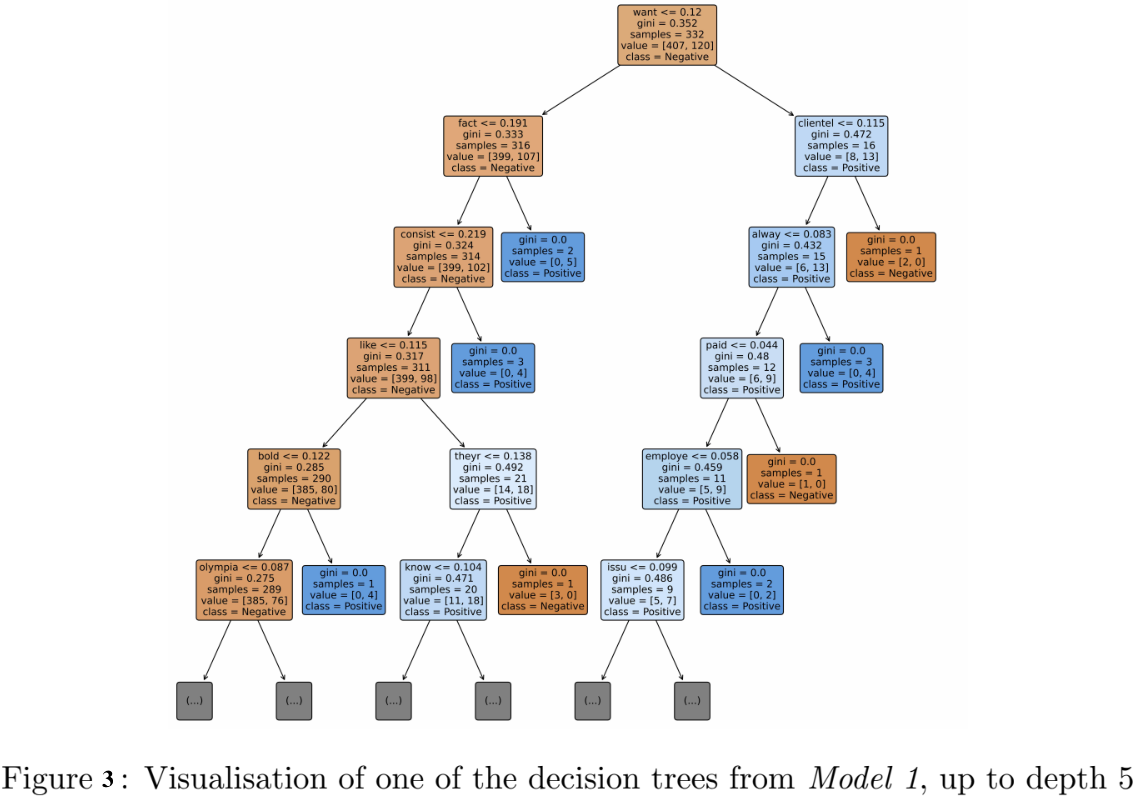
Figure 3 shows a visualisation of one of the decision trees from Model 1, up to depth 5.
Note: when the models are applied to the test set, out-of-vocabulary terms are ignored.
Results
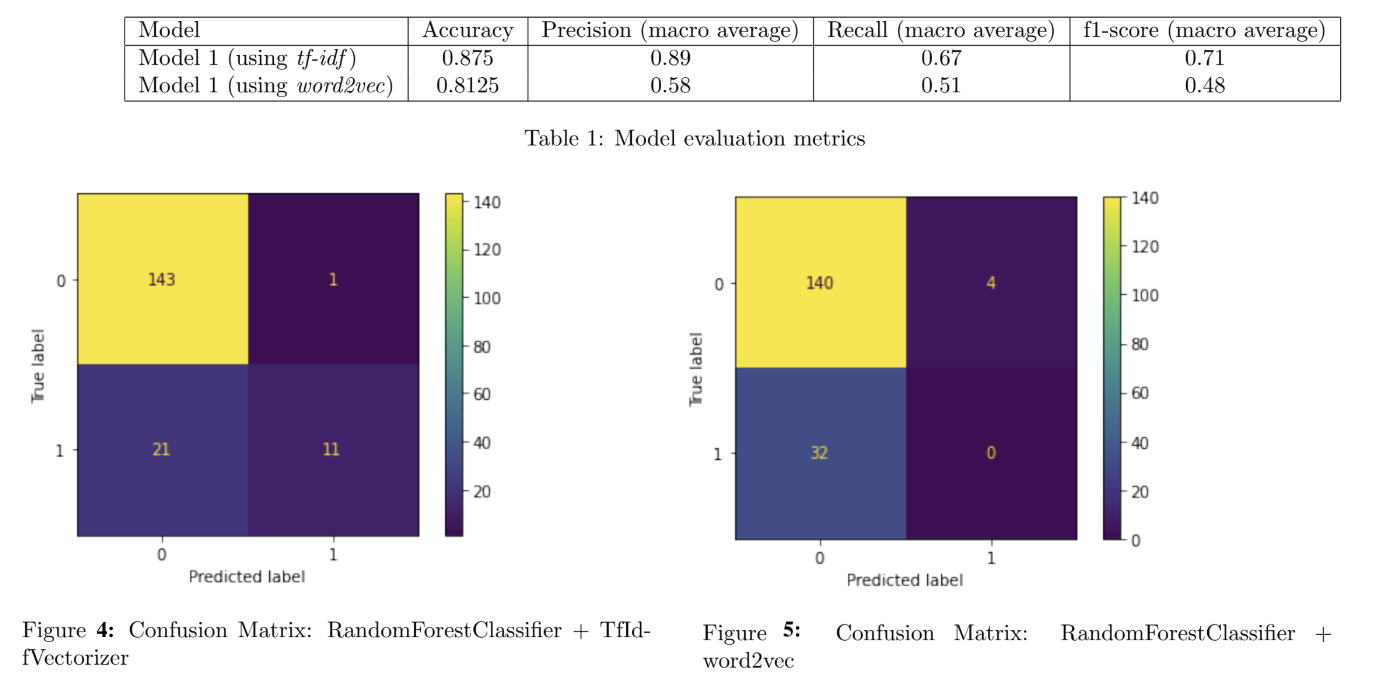
The two models were applied to the test set and evaluated. Table 1 compares the models based on a number classification evaluation metrics: Accuracy, Precision, Recall, and f1-score. Macro averages are provided for those latter 3 metrics - since there is a class imbalance in the data, this should be taken into account when evaluating the models’ performance. The first model, RandomForestClassifer with TfidfVectorizer, performed better across all metrics. Figures 4 and 5 show the respective confusion matrices.
Note: This post is based on a report written for an assignment as part of my degree in Machine Learning & Data Science at Imperial College London. The assignment was part of Unstructured Data Analysis module taught by Dr A. Calissano (all credit due for the assignment setting, the goals and objectives of the modelling, and the selection and provision of the dataset).